이번 글은 칼만 필터의 업데이트 과정을 기하학적으로 설명한다.
먼저 힐베르트 공간(Hilbert Space)을 이해해야 한다. 칼만 필터의 수식은 복잡한 행렬 연산으로 이루어져 있는데, 이 수식들을 힐베르트 공간이라는 기하학적 관점에서 바라보면, 직관적으로 해석이 가능해진다.
힐베르트 공간을 전부 설명하지는 않을 것이다. 가장 중요한 내용은 확률변수(Random Variable)를 Vector로 취급한다는 것이다.
즉 PDF가 힐베르트 공간에서는 벡터로 해석이 되고, 통계학적 내용들이 기하적 세상에서 다음과 같이 해석된다.
- 확률변수 (x) → 벡터
- 표준편차 (σx) → 벡터의 길이 (화살표가 길수록 불확실하다)
- 공분산 (E[XY]) → 내적 <x, y> (두 화살표의 방향이 얼마나 비슷한가)
- 독립성 (Independent) → 직교 (서로 아무런 관계가 없다)
- 최적 추정 (Estimation) → 투영 (Projection)
Hilbert Space and the Projection Theorem
우리가 추정하고자 하는 시스템의 상태와 관측값은 모두 노이즈를 포함한 확률변수이다. 이를 벡터 공간으로 옮겨오면, 칼만 필터의 최적 추정은 오차 벡터의 길이를 최소화하는 문제, 즉 기하학적인 최단 거리를 찾는 문제가 된다.
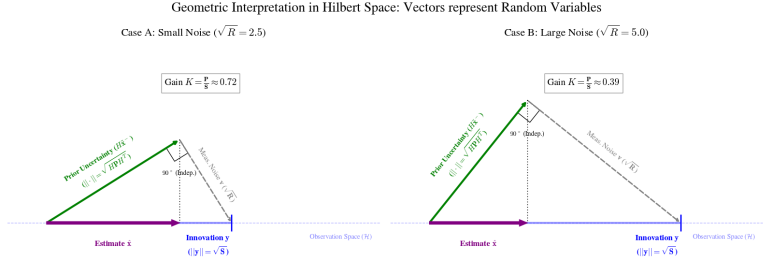
그림에서 보라색 벡터가 시작하는 지점은 현재의 예측된 확률 분포를 나타낸다. 여기서 뻗어 나가는 세 가지 핵심 벡터는 다음과 같다:
- 사전 불확실성 (녹색 벡터): 모델 예측이 가지고 있는 불확실성이다. 벡터의 길이는 사전 공분산 HPH^T의 제곱근에 해당한다.
- 측정 노이즈 (v, 회색 벡터): 센서가 가진 고유한 불확실성이다. 벡터의 길이는 측정 노이즈 공분산 R의 제곱근이다.
- Innovation (y, 파란색 벡터): 실제 센서 측정값과 예측값의 차이다. 이는 신호의 불확실성과 노이즈가 합쳐진 결과물이며, 벡터 합으로 표현된다.
여기서 가장 중요한 기하학적 특징은 독립성(Independence)과 직교성(Orthogonality)의 관계이다. 시스템의 상태 오차와 측정 노이즈는 통계적으로 서로 독립이므로, 기하학적으로 두 벡터는 90˚를 이루며 직교한다. 따라서 이노베이션 벡터의 길이(분산 S)는 피타고라스 정리에 의해 S = HPH^T + R로 정의된다.
칼만 필터의 목적은 관측된 정보(Innovation) 중에서 우리가 신뢰할 수 있는 '진짜 신호'의 성분을 걸러내는 것이다. 기하학적으로 이것은 사전 불확실성 벡터를 관측 공간으로 수직 투영(Orthogonal Projection) 시키는 것과 같다. (보라색 벡터의 끝이 우리가 도달하고 싶은 True(초록색 벡터의 끝)에 가장 가까운 지점을 생각해 보면 된다.)
그림의 보라색 벡터가 바로 이 투영의 결과이다. 칼만 게인 K는 전체 이노베이션 벡터 길이(루트(S)) 대비 투영된 그림자의 길이 비율을 결정하는 계수이다.

Case A와 같이 측정 노이즈가 작을수록 초록색 벡터는 바닥으로 더 길게 투영되며, 이는 관측값을 더 많이 신뢰한다는 것을 의미한다(K = 0.72). 반면 Case B처럼 노이즈가 크면 투영된 그림자는 짧아지고, 관측값의 반영 비율이 줄어든다(K = 0.39).
결국 칼만 업데이트 수식은 확률변수 벡터 공간에서 노이즈 성분을 제거하고 신호 성분만을 추출하기 위한 직교 투영 연산임을 알 수 있다.
하지만 이 1차원적인 투영 해석은 업데이트의 크기에 대한 직관을 제공할 뿐, 다차원 상태 공간에서 업데이트가 이루어지는 방향까지 완전히 설명하지는 못한다. 실제 상태 변수들 간의 상관관계가 업데이트 방향을 어떻게 비틀어 놓는지에 대해서는 다음 섹션에서 다룬다.
Update Direction and the Role of Covariance in State Space
앞선 힐베르트 공간에서의 해석이 업데이트의 크기를 결정하는 과정이었다면, 상태 공간에서의 해석은 업데이트의 방향을 결정하는 원리를 보여준다. 칼만 필터가 단순한 가중 평균 필터와 차별화되는 결정적인 이유가 바로 이 방향성에 있다.

위 그림은 관측되지 않은 상태 변수까지도 수정해내는 칼만 필터의 기하학적 원리를 담고 있다.
그림의 원점은 현재의 예측 상태를 나타낸다. 여기서 파란색 점은 관측된 혁신(Innovation, y)이다. 직관적으로는 관측된 정보가 위치한 방향, 즉 파란색 점선인 관측 축(Measurement Axis, H)을 따라 상태를 수정해야 할 것 같다. 하지만 그림의 보라색 화살표(Update Vector)는 관측 축을 벗어나 비스듬한 방향을 가리키고 있다.
이러한 방향의 비틀림을 만들어내는 핵심 요소들은 다음과 같다:
- 녹색 타원 (Prior Covariance P): 타원의 기울어진 모양은 상태 변수들 간의 상관관계(Correlation)를 나타낸다. 타원의 장축(Major Axis)은 현재 불확실성이 가장 큰 방향을 의미한다.
- 붉은 점선 벡터 (PHT): 이것이 업데이트의 방향이다. 관측 행렬의 전치(HT)는 관측 공간의 정보를 상태 공간으로 가져오지만, 공분산 행렬 P가 곱해지면서 그 벡터를 타원의 장축 방향(불확실성이 큰 방향)으로 회전시킨다.
- 주황색 선 (Ratio): 앞서 힐베르트 공간 섹션에서 구한 신뢰도 비율이다. 그림의 주황색 선(Ratio = 0.74)이 이를 나타낸다. 전체 이노베이션 중에서 노이즈를 제외한 신호의 비율만큼 벡터의 길이를 조절한다.
그림에서 최종 업데이트 벡터(보라색)인 Ky는 수학적으로 방향 성분과 스칼라 성분의 결합으로 분해하여 해석할 수 있다.

여기서 주목할 점은 업데이트 벡터(보라색)의 기울기다. 만약 단순한 추정기였다면 업데이트 벡터가 관측 축(주황색 선) 위에 누워 있었겠지만, 칼만 필터에서는 P 행렬의 선형 변환에 의해 벡터가 관측 축으로부터 비스듬하게 들어올려진다.
이러한 기하학적 구조 덕분에 칼만 필터는 직접 관측하지 않은 변수도 추정할 수 있다. 예를 들어, 위치만 측정하는 센서를 사용하더라도, 위치와 속도가 양의 상관관계(타원의 기울기)를 가진다면, 위치의 오차를 수정할 때 속도(PHT 방향)도 함께 수정하게 된다.
[칼만 필터 - 10] 칼만 필터 업데이트의 기하학적 이해
이번 글은 칼만 필터의 업데이트 과정을 기하학적으로 설명한다. 먼저 힐베르트 공간(Hilbert Space)을 ...
blog.naver.com