확률론이나 칼만 필터, EM 알고리즘 등을 공부하다 보면, 결국 핵심은 '두 확률 분포의 차이와 유사도를 어떻게 평가할 것인가'로 이어진다는 것을 알게 된다.
최근에 공부하던 힐베르트 공간(Hilbert Space)에서 바타차리아 거리(Bhattacharyya Distance)를 해석할 수 있음을 알게 되어, 이와 관련된 내용으로 글을 작성한다.
바타차리아 거리(Bhattacharyya Distance)
Bhattacharyya 거리는 두 확률 분포의 겹침 정도를 측정하여 분리성을 판단하는 데 주로 사용된다. 먼저 Bhattacharyya Coefficient (BC)를 다음과 같이 정의한다.

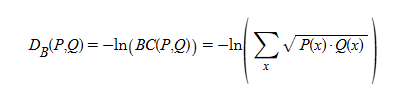
수식을 살펴보면, P(x)와 Q(x)가 동시에 높은 값을 가지는 영역이 많을수록 P(x) · Q(x)의 합이 커지고, 결과적으로 로그 앞의 마이너스 부호로 인해 거리는 작아진다. 반대로 두 분포가 전혀 겹치지 않는다면 P(x) · Q(x)는 모든 x에서 0이 되어 거리는 무한대가 된다.

위 그림은 서로 다른 평균과 분산을 가진 두 가우시안 분포(P, Q)와, 그 사이의 Bhattacharyya 거리를 시각화한 것이다.
- 보라색 영역 (Overlap Kernel): 그림 중앙의 보라색 빗금 친 영역은 두 분포의 기하평균 곡선이다. 이 영역의 넓이가 바로 BC이다.
- 곱셈: 두 분포가 동시에 높은 확률을 가질 때만 값이 커진다. 즉, 한쪽이라도 확률이 0에 가까우면 보라색 영역은 사라진다.
- 로그의 역할:
- 두 분포가 완벽하게 일치하면 겹치는 넓이(BC)는 1이 되고, 거리는 -ln(1) = 0이 된다.
- 반대로 두 분포가 전혀 겹치지 않으면 넓이(BC)는 0이 되고, 거리는 -ln(0) → ∞로 발산한다.
결국 바타차리아 거리는 "두 분포가 공유하는 보라색 영역이 넓을수록 거리가 가깝다"라고 판단하는 지표임을 알 수 있다.
Bhattacharyya 계수의 기하학적 해석: 구면 위의 각도
일반적인 확률 밀도 함수 P(x)는 모두 더하면(적분하면) 1이 된다는 성질을 가진다.
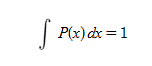
이 상태로는 기하학적으로 다루기 까다롭다. 하지만 여기에 루트를 씌워 새로운 함수를 정의해 보자. 이제 이 함수 f(x)의 L2 Norm (벡터의 길이)을 계산한다.
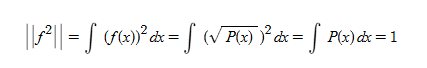
즉, 임의의 확률 분포 P에 루트를 씌운 루트(P)는 Hilbert 공간상에서 길이가 항상 1인 Unit Vector가 된다. 이것은 모든 확률 분포들이 반지름이 1인 Hypersphere의 표면 위에 존재한다는 것을 의미한다.
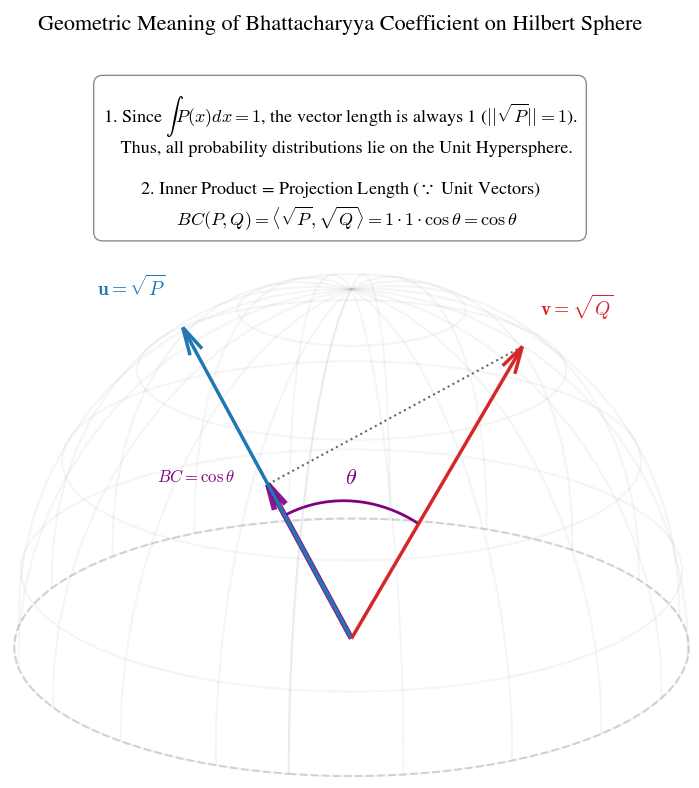
이제 두 확률 분포 P와 Q를 각각 단위 벡터 u = 루트(P), v = 루트(Q)로 생각할 수 있다. Hilbert 공간에서 두 함수의 내적은 다음과 같이 정의된다.
나머지는 네이버 블로그에서 확인해주세요
[통계적 거리 (Statistical Distance)] 두 확률 분포의 거리 측정: 바타차리아 거리 (Bhattacharyya Distance)
확률론이나 칼만 필터, EM 알고리즘 등을 공부하다 보면, 결국 핵심은 '두 확률 분포의 차이와 유사...
blog.naver.com